Abstract
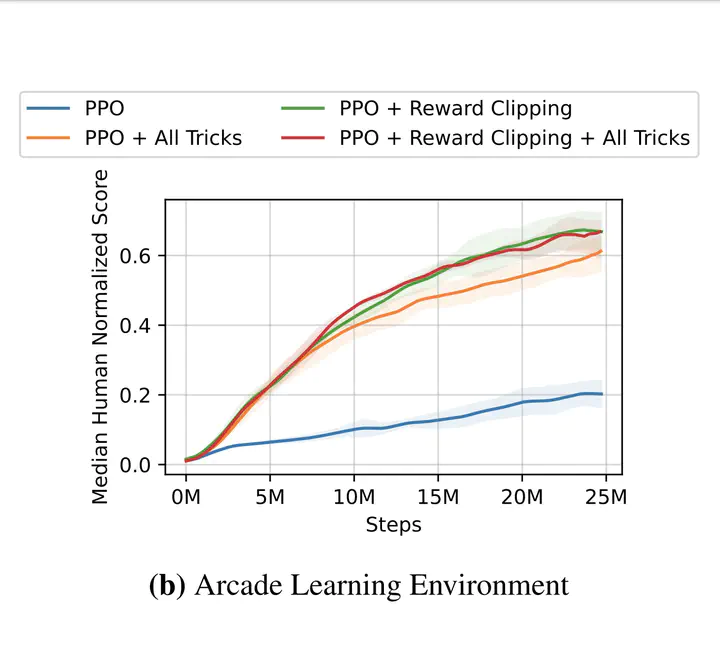
Despite its successes in a variety of domains, reinforcement learning relies heavily on well-normalized and dense environmental rewards. DreamerV3, a recent model-based RL method, has achieved state-of-the-art results on a wide range of benchmarks using several implementation tricks to overcome these limitations with a single set of hyperparameters. Some of these tricks, such as percentile-based return scaling are introduced to normalize returns, while others are presented as solutions to specific issues faced by actor-critic algorithms. However, the impact of each of these tricks has not been examined in isolation outside of DreamerV3, which uses a much larger model and several other orthogonal improvements over prior work. We implement each trick applicable to actor-critic learning as an extension to Proximal Policy Optimization (PPO), a popular reinforcement learning baseline, and demonstrate that they do not transfer as general improvements to PPO. We present extensive ablation studies totaling over 10,000 A100 hours of compute on the Arcade Learning Environment and the Deepmind Control Suite. Though our experiments demonstrate that these tricks do not generally outperform PPO, we identify cases where they succeed and offer insight into the relationship between the implementation tricks. In particular, our method performs comparably to PPO on Atari games with reward clipping and significantly outperforms PPO without reward clipping.
Ryan Sullivan
Computer Science PhD Candidate
rsulli@umd.edu
My research interests include reinforcement learning, curriculum learning, and training agents in multi-agent or open-ended environments.